Using SQL¶
marimo lets you mix and match Python and SQL: Use SQL to query Python dataframes (or databases like SQLite and Postgres), and get the query result back as a Python dataframe.
For a video overview on how to use SQL in marimo, watch our YouTube tutorial.
To create a SQL cell, you first need to install additional dependencies, including duckdb:
Examples
For example notebooks, check out
examples/sql/ on GitHub.
Example¶
In this example notebook, we have a Pandas dataframe and a SQL cell that queries it. Notice that the query result is returned as a Python dataframe and usable in subsequent cells.
Creating SQL cells¶
You can create SQL cells in one of three ways:
- Right-click an "add cell" button ("+" icon) next to a cell and choose "SQL cell"
- Convert a empty cell to SQL via the cell context menu
- Click the SQL button that appears at the bottom of the notebook
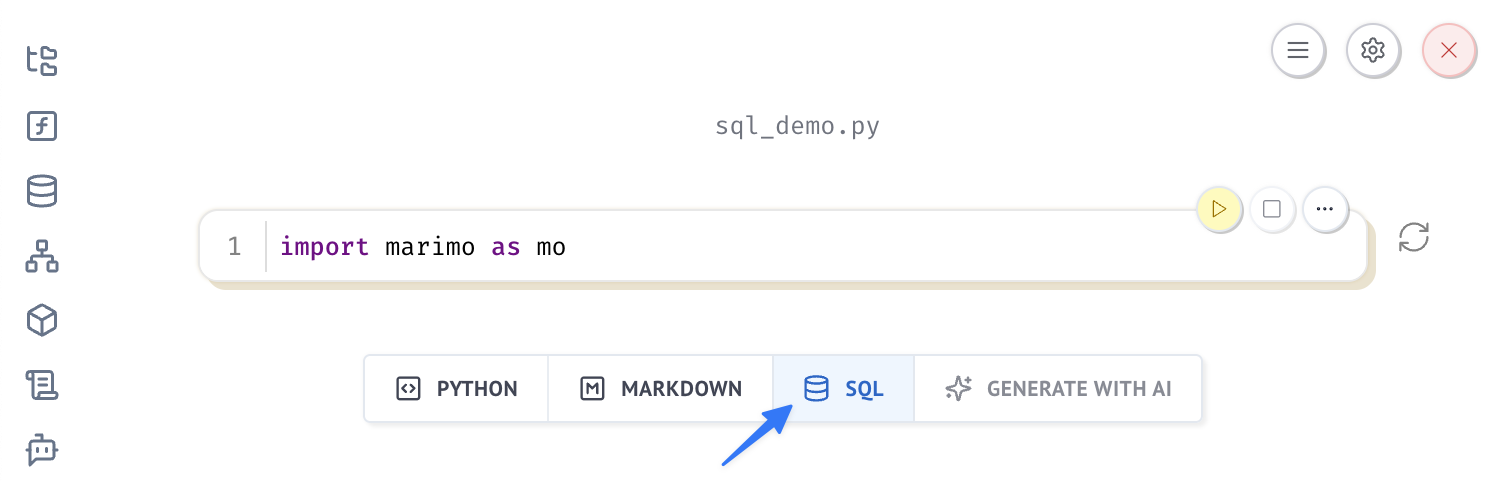
This creates a "SQL" cell for you, which is syntactic sugar for Python code. The underlying code looks like:
Notice that we have an output_df variable in the cell. This contains
the query result, and is a Polars DataFrame (if you have polars installed) or
a Pandas DataFrame (if you don't). One of them must be installed in order to
interact with the query result.
The SQL statement itself is an f-string, letting you
interpolate Python values into the query with {}. In particular, this means
your SQL queries can depend on the values of UI elements or other Python values,
and they are fit into marimo's reactive dataflow graph.
SQL Output Types¶
marimo supports different output types for SQL queries, which is particularly useful when working with large datasets. You can configure this in your application configuration in the top right of the marimo editor.
The available options are:
native: Uses DuckDB's native lazy relation (recommended for best performance)lazy-polars: Returns a lazy Polars DataFramepandas: Returns a Pandas DataFramepolars: Returns an eager Polars DataFrameauto: Automatically chooses based on installed packages (first triespolarsthenpandas)
For best performance with large datasets, we recommend using native to avoid loading the entire result set into memory and to more easily chain SQL cells together. By default, only the first 10 rows are displayed in the UI to prevent memory issues.
Set a default
The default output type is currently auto, but we recommend explicitly setting the output type to native for best performance with large datasets or polars if you need to work with the results in Python code. You can configure this in your application settings.
Reference a local dataframe¶
You can reference a local dataframe in your SQL cell by using the name of the Python variable that holds the dataframe. If you have a database connection with a table of the same name, the database table will be used instead.
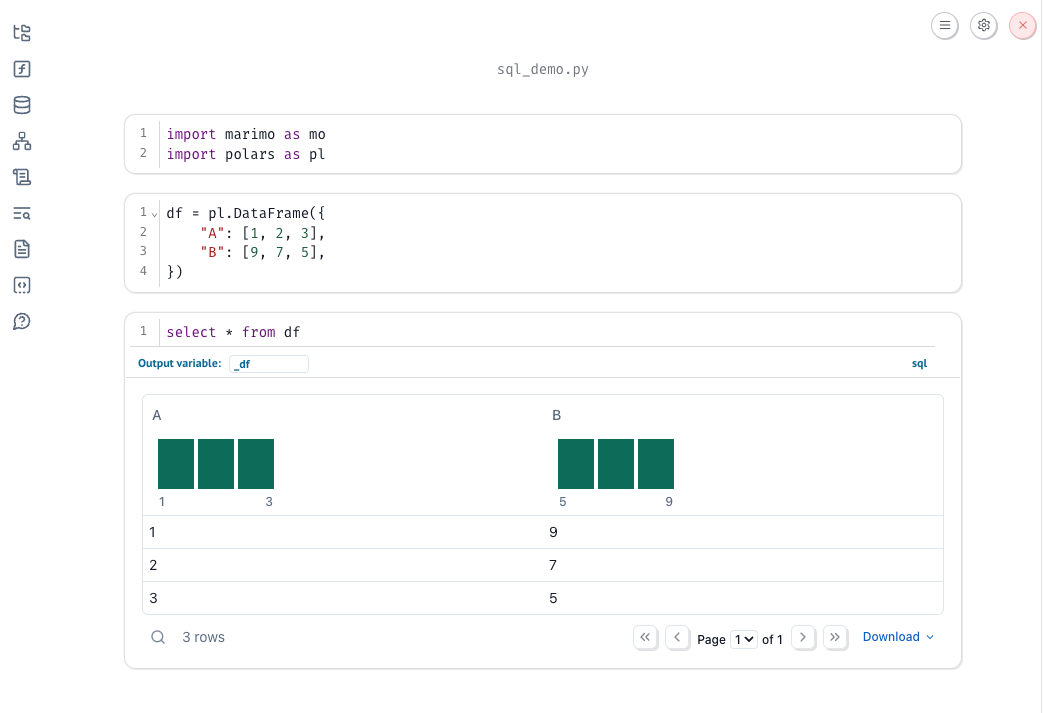
Since the output dataframe variable (_df) has an underscore, making it private, it is not referenceable from other cells.
Reference the output of a SQL cell¶
Defining a non-private (non-underscored) output variable in the SQL cell allows you to reference the resulting dataframe in other Python and SQL cells.
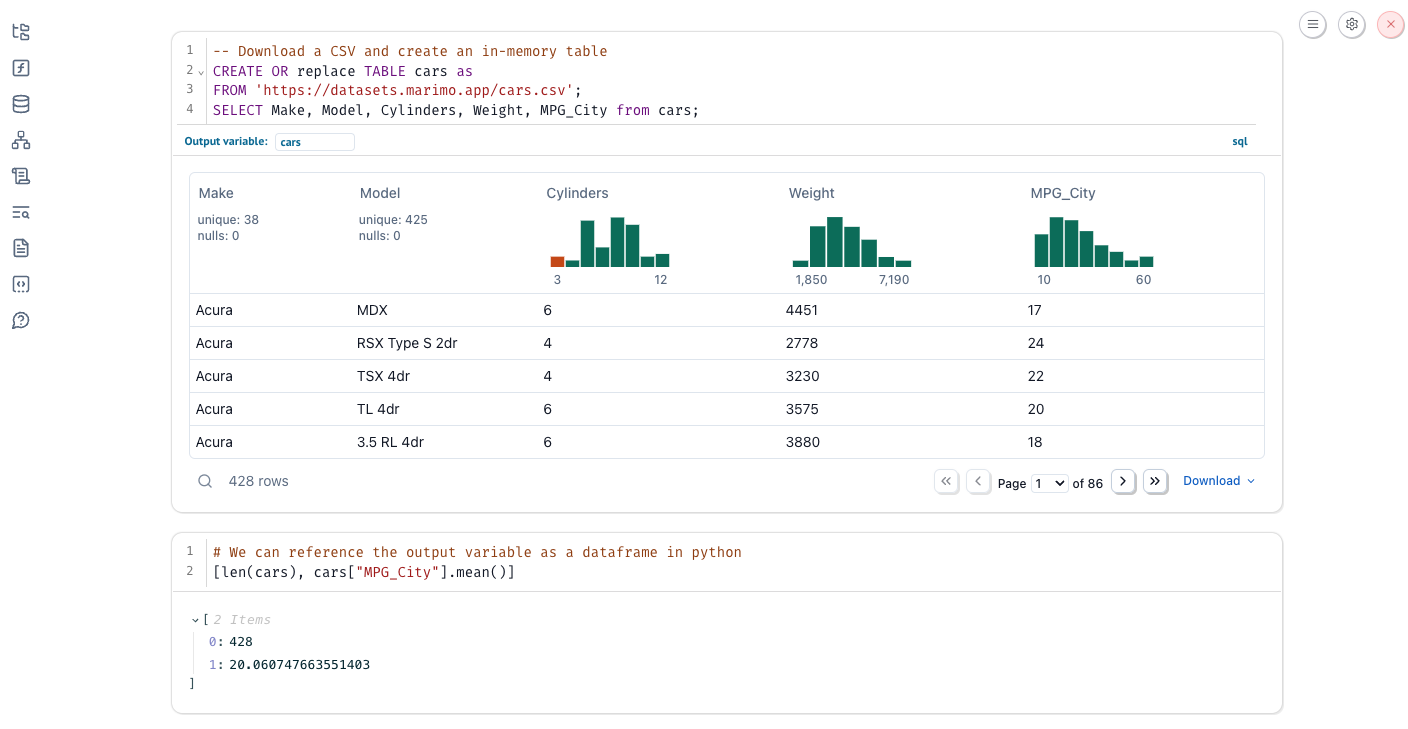
Querying files, databases, and APIs¶
In the above example, you may have noticed we queried an HTTP endpoint instead of a local dataframe. We are not only limited to querying local dataframes; we can also query files, databases such as Postgres and SQLite, and APIs:
-- or
SELECT * FROM 's3://my-bucket/file.parquet';
-- or
SELECT * FROM read_csv('path/to/example.csv');
-- or
SELECT * FROM read_parquet('path/to/example.parquet');
For a full list you can check out the duckdb extensions. You can also check out our examples on GitHub.
Escaping SQL brackets¶
Our "SQL" cells are really just Python under the hood to keep notebooks as pure Python scripts. By default, we use f-strings for SQL strings, which allows for parameterized SQL like SELECT * from table where value < {min}.
To escape real {/} that you don't want parameterized, use double {{...}}:
Connecting to a custom database¶
There are two ways to connect to a database in marimo:
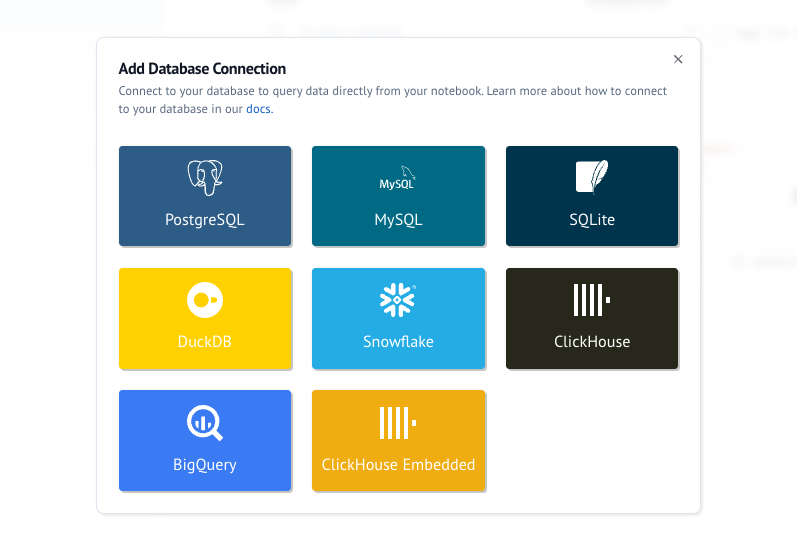
1. Using the UI¶
Click the "Add Database Connection" button in your notebook to connect to PostgreSQL, MySQL, SQLite, DuckDB, Snowflake, or BigQuery databases. The UI will guide you through entering your connection details securely. Environment variables picked up from your dotenv can be used to fill out the database configuration fields.
If you'd like to connect to a database that isn't supported by the UI, you can use the code method below, or submit a feature request.
2. Using Code¶
You can bring your own database via a connection engine with one of the following libraries
By default, marimo uses the in-memory duckdb connection.
List of supported databases
Updated: 2025-04-30. This list is not exhaustive.
| Database | Library |
|---|---|
| Amazon Athena | sqlalchemy, sqlmodel, ibis |
| Amazon Redshift | sqlalchemy, sqlmodel |
| Apache Drill | sqlalchemy, sqlmodel |
| Apache Druid | sqlalchemy, sqlmodel, ibis |
| Apache Hive and Presto | sqlalchemy, sqlmodel |
| Apache Solr | sqlalchemy, sqlmodel |
| BigQuery | sqlalchemy, sqlmodel, ibis |
| ClickHouse | clickhouse_connect, chdb |
| CockroachDB | sqlalchemy, sqlmodel |
| Databricks | sqlalchemy, sqlmodel, ibis |
| dlt | ibis |
| Datafusion | ibis |
| DuckDB | duckdb |
| EXASolution | sqlalchemy, sqlmodel, ibis |
| Elasticsearch (readonly) | sqlalchemy, sqlmodel |
| Firebolt | sqlalchemy, sqlmodel |
| Flink | ibis |
| Google Sheets | sqlalchemy, sqlmodel |
| Impala | sqlalchemy, sqlmodel, ibis |
| Microsoft Access | sqlalchemy, sqlmodel |
| Microsoft SQL Server | sqlalchemy, sqlmodel, ibis |
| MonetDB | sqlalchemy, sqlmodel |
| MySQL | sqlalchemy, sqlmodel, ibis |
| OpenGauss | sqlalchemy, sqlmodel |
| Oracle | sqlalchemy, sqlmodel, ibis |
| PostgreSQL | sqlalchemy, sqlmodel, ibis |
| PySpark | ibis |
| RisingWave | ibis |
| SAP HANA | sqlalchemy, sqlmodel |
| Snowflake | sqlalchemy, sqlmodel, ibis |
| SQLite | sqlalchemy, sqlmodel, ibis |
| Teradata Vantage | sqlalchemy, sqlmodel |
| TimePlus | sqlalchemy, sqlmodel |
| Trino | sqlalchemy, sqlmodel, ibis |
Define the engine as a Python variable in a cell:
ClickHouse Connect enables remote connections to ClickHouse databases. Refer to the official docs for more configuration options.
Warning
chDB is still new. You may experience issues with your queries. We recommend only using one connection at a time. Refer to chDB docs for more information.
import chdb
connection = chdb.connect(":memory:")
# Supported formats with examples:
":memory:" # In-memory database
"test.db" # Relative path
"file:test.db" # Explicit file protocol
"/path/to/test.db" # Absolute path
"file:/path/to/test.db" # Absolute path with protocol
"file:test.db?param1=value1¶m2=value2" # With query parameters
"file::memory:?verbose&log-level=test" # In-memory with parameters
"///path/to/test.db?param1=value1" # Triple slash absolute path
marimo will auto-discover the engine and let you select it in the SQL cell's connection dropdown.
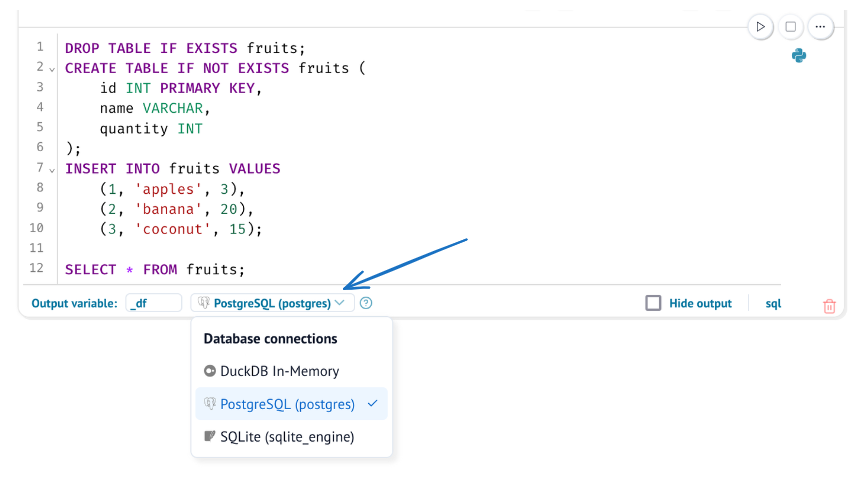
Database, schema, and table auto-discovery¶
marimo will automatically discover the database connection and display the database, schemas, tables, and columns in the Data Sources panel. This panels lets you quickly navigate your database schema and reference tables and columns to pull in your SQL queries.
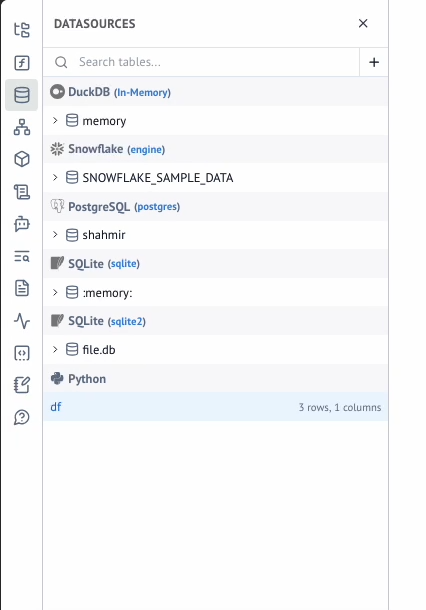
Note
By default, marimo auto-discovers databases and schemas, but not tables and columns (to avoid performance issues with large databases). You can configure this behavior in your pyproject.toml file. Options are true, false, or "auto". "auto" will determine whether to auto-discover based on the type of database (e.g. when the value is "auto", Snowflake and BigQuery will not auto-discover tables and columns while SQLite, Postgres, and MySQL will):
Catalogs¶
marimo supports connecting to Iceberg catalogs. You can click the "+" button in the Datasources panel or manually create a PyIceberg Catalog connection. PyIceberg supports a variety of catalog implementations including REST, SQL, Glue, DynamoDB, and more.
from pyiceberg.catalog.rest import RestCatalog
catalog = RestCatalog(
name="catalog",
warehouse="1234567890",
uri="https://my-catalog.com",
token="my-token",
)
Catalogs will appear in the Datasources panel, but they cannot be used as an engine in SQL cells. However, you can still load the table and use it in subsequent Python or SQL cells.
Utilities¶
marimo provides a few utilities when working with SQL
SQL Linter
Lint your SQL code and provide better autocompletions and error highlighting.
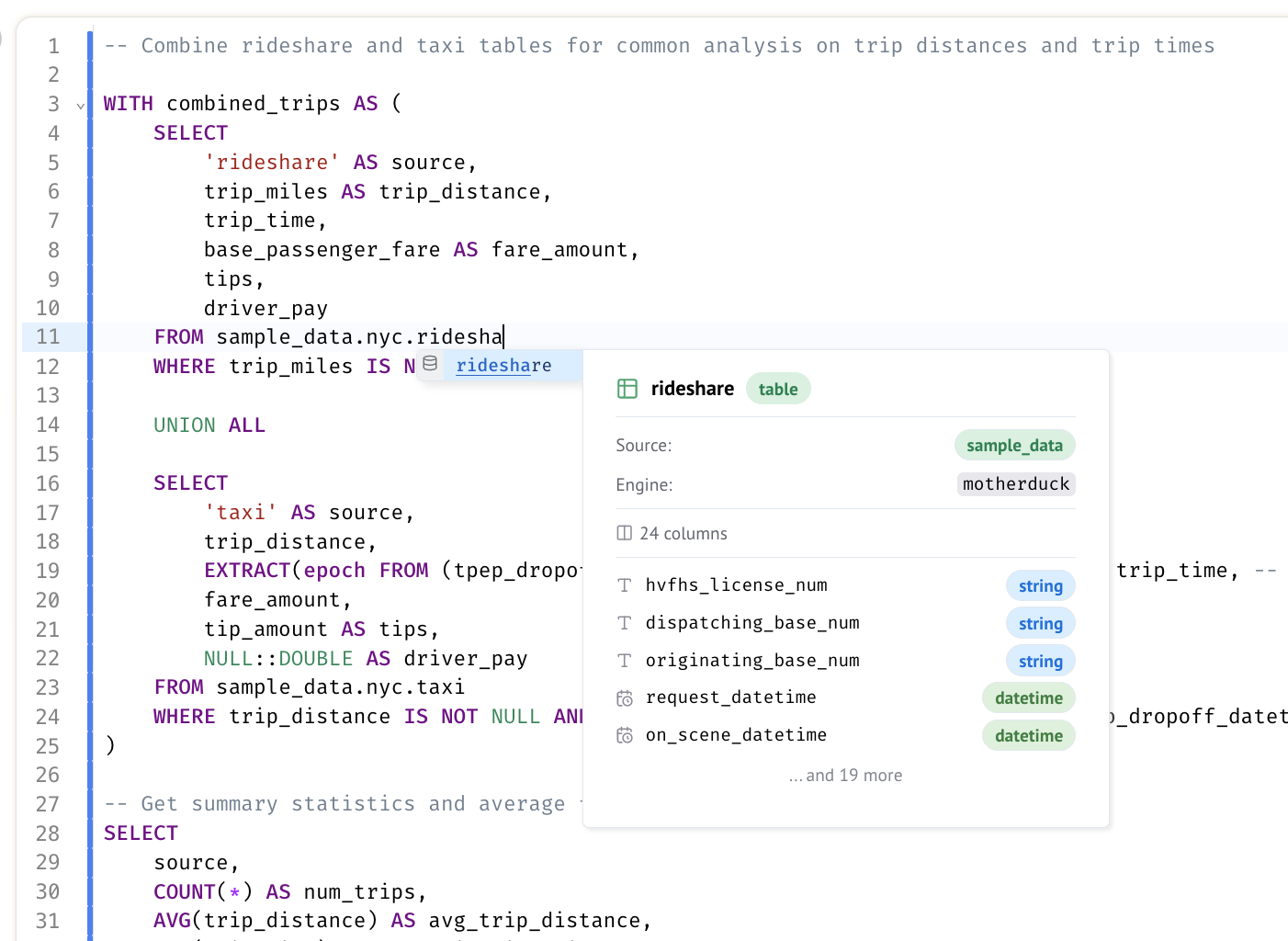
To disable the linter, you can set the sql_linter configuration to false in your pyproject.toml file or disable it in the marimo editor's settings menu.
SQL Formatting
Click on the paint roller icon at the bottom right of the SQL cell to format your SQL code.
SQL Mode
For In-Memory DuckDB, marimo offers a Validate mode that will validate your SQL as you write it.
Under the hood, this runs a debounced query in EXPLAIN mode and returns the parsed errors.
Interactive tutorial¶
For an interactive tutorial, run
at your command-line.
Examples¶
Check out our examples on GitHub.